浏览器是怎样工作的:渲染引擎,HTML解析(连载二) 携程设计委
第一个符合规则的子字符串是”2″,根据规则#5它是一个术语。第二个匹配是”2 + 3″,符合第二条规则——一个术语紧跟一个操作符再跟另外一个术语。下一个匹配出现在输入结束时。”2 + 3 – 1″是一个表达式,因为我们已知“2+3”是一个术语,所以符合第二条规则。 “2 + + “不会匹配任何规则,所以是无效的输入。
解析因为解析是渲染引擎中一个很重要的处理,我们会讲的略深入一些。让我们从一个小的解析介绍开始。
HTML解析器HTML解析器的工作是解析HTML标记到解析树。
自上而下解析器从上层规则开始,它会把”2 + 3″定义为表达式,然后定义”2 + 3 – 1″为表达式(定义表达式的过程中也会匹配其它规则,但起点是最高级别规则)。
元素嵌套
为防止一表单的嵌套,第二个表单会被忽略。代码:
然后状态改变为“before head”。我们收到”body”时,会隐式创建一个HTMLHeadElement,尽管我们没有这个标签,它也会被创建并添加到树中。
分词器识别这些符号并将其送入树构建者,然后继续分析处理下一个符号,直到输入结束。
<table> <table> <tr><td>inner table</td></tr> </table> <tr><td>outer table</td></tr> </table>Webkit会改变层级关系,把它们处理成两个相临的表格:
语法解析是基于文档所遵循的语法规则——书写所用的语言或格式——来进行的。每一种可以解析的格式必须由确定的语法与词汇组成。这被称之为。 人类语言并非此种语言,所以不能用常规的解析技术来解析。
DOM与标签几乎有着一一对应的关系,如下面的标签
操作符是加号或减号。
HTML与XML相当接近。XML有许多可用的解析器。HTML还有一个XML变种叫XHTML,那么它们主要区别在哪里呢?区别在于HTML应用更加”宽容”,它容许你漏掉一些开始或结束标签等。它整个是一个“软”句法,不像XML那样严格死板。 总的来说这一看似细微的差别造成了两个不同的世界。一方面这使得HTML很流行,因为它包容你的错误,使网页作者的生活变得轻松。另一方面,它使编写语法格式变得困难。所以综合来说,HTML解析并不简单,现成的上下文相关解析器搞不定,XML解析器也不行。
词汇:我们的语言可以包含整数,加号和减号。
渲染引擎会解析HTML文档并把标签转换成内容树中的DOM节点。它会解析style元素和外部文件中的样式数据。样式数据和HTML中的显示控制将共同用来创建另一棵树——。
<table> <tr><td>outer table</td></tr> </table> <table> <tr><td>inner table</td></tr> </table>代码:
<html> <body> Hello world </body> </html>初始状态是”Data state”,当遇到”<“时状态改为“Tag open state”。吃掉”a-z”字符组成的符号后产生了”Start tag token”,状态变更为“Tag name state”。我们一直保持此状态,直到遇到”>”。每个字符都被追加到新的符号名上。在我们的例子中,解出的符号就是”html”。
图 4:Mozilla的Gecko渲染引擎主要流程()
与HTML一样,DOM规范也由w3c组织制订。参考: 这是一个操作文档的通用规范。有一个专门的模块定义HTML特有元素:
Webkit使用两款知名的解析器生成工具:Flex用于创建词法分析器,Bison用于创建解析器 (你也许会看到它们以Lex和Yacc的名字存在)。Flex的输入文件是符号的正则表达式定义,Bison的输入文件是BNF格式的句法定义。
迷失的表格像下面的例子这样,一个表格包含在另外一个表格的内容中,但不是在外部表格的单元格里:
从图3和图4中可以看出,尽管Webkit与Gecko使用略微不同的术语,这个过程还是基本相同的。
渲染树包含带有颜色,尺寸等显示属性的矩形。这些矩形的顺序与显示顺序一致。
Webkit 是一个开源的渲染引擎,它源自Linux平台上的一个引擎,经过Apple公司的修改可以支持Mac与Windows平台。更多信息可以参考:。
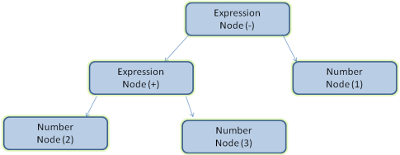
term operation 3 – 1
让我们看看这两种解析器将怎样解析我们的例子:
INTEGER :0|[1-9][0-9]* PLUS : + MINUS: -
如你所见,整型是由正则表达式定义的。
图 7:编译过程(源码,解析,解析树,转换,机器码)。term + 3 – 1
解析器分析输入符号生成文档,并构建文档树。如果文档格式良好,解析工作会很简单。 不幸的是,我们要处理很多格式不良的HTML文档,解析器需要宽容这些错误。 我们至少需要照顾下列错误: 1. 元素必需被插入在正确的位置。未关闭的标签应该一一关闭,直到可以添加新元素。 2. 不允许直接添加元素。用户可能会漏掉一些标签,比如:HTML HEAD BODY TBODY TR TD LI(我遗漏了什么?)。 3. 在inline元素里添加block元素时,应关闭所有inline元素,再添加block元素。 4. 如果以上不起作用,关闭所有元素,直到可以添加,或者忽略此标签。
默认情况下渲染引擎可以显示HTML,XML文档以及图片。 通过插件(浏览器扩展)它可以显示其它类型文档。比如使用PDF viewer插件显示PDF文件。我们会在一个专门的章节讨论插件与扩展。在这一节我们将专注渲染引擎的主要用途——显示用CSS格式化的HTML与图片。
expression := term operation term operation := PLUS | MINUS term := INTEGER | expression我们说过常规解析器只能解析上下文无关语法的语言。这种语言的一个直觉的定义是它的句法可以用BNF完整的表达。其规范定义请参考
当我们说树中包含DOM节点时,意思就是这个树是由实现了DOM接口的元素组成。这些实现包含了其它一些浏览器内部所需的属性。
HTML5规范里对解析算法有具体的说明,解析由两部分组成:分词与构建树。

