一个小运营用过的爬虫和自动化走过的那些路
10年前的时候,我还只是一个学过几天C语言的学生,想要搞一个爬虫,就只能用C语言了。
当时的思路是通过cURL等工具下载好HTML代码,然后传入给程序,获取到自己想要数据。
技术点:dos下管道命令截取字符
代码:textclip.c
使用CS版本截取字符串,原理和上一代一样,不再是命令行工具了,而且不需要其他程序配合。
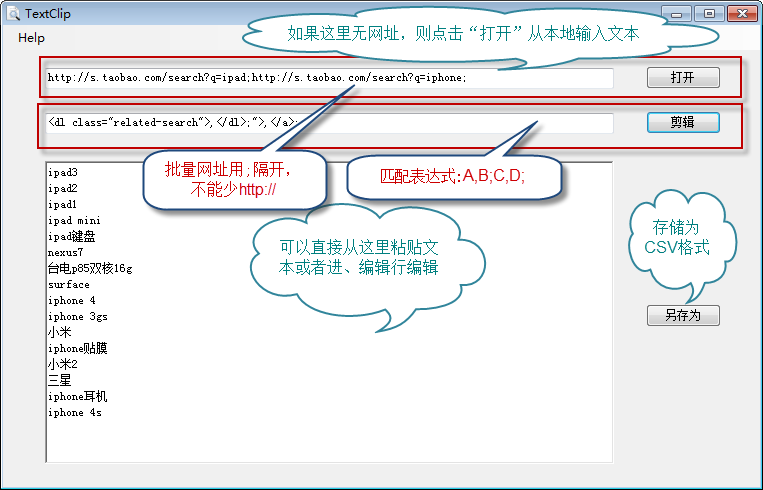
程序:textClipCS.exe
写一个html,利用js发起ajax请求,获取到数据,然后整理为需要的数据格式。
具体代码忘了存了,这个版本使用时间很短,优点在于使用浏览器操作,不受平台限制。
第三代2:
使用windows的批处理写自动化处理关键词,主要代码都是js,bat文件就是一个调用js文件的方式,不用html,更快捷。
优点:可以给很多人用,操作简单,但是要做好参数文件配置。
感兴趣的可以看看这个代码,虽然运行不了,但是原理是对的,当年用了很久。
代码:关键词-车型分析 - V1.2.bat
还是使用js,但是放到了油猴脚本管理器里面,用浏览器运行,可以自动化的操作网页或者统计网页上的数据。
代码都很简单,可以自己看看,这儿有2个例子。
代码:聚划算搜索页面想买和付款数量金额统计.user.js
代码:速卖通自动点击评价.user.js
在多年的数据整理中,返现最后都还是要用excel,那我为什么不用VBA来获取数据。
开始使用vba编程,获取数据,直接发起request求情,并解析数据,处理数据。
数据的请求和解析代码在这,具体的输出和分析处理就不透露了,我都还在用这些代码。
下面这个就是通过vba获取数据,分析淘宝的关键词的数据和搜索关键词的销量和价格,但是现在用不了,淘宝屏蔽了。
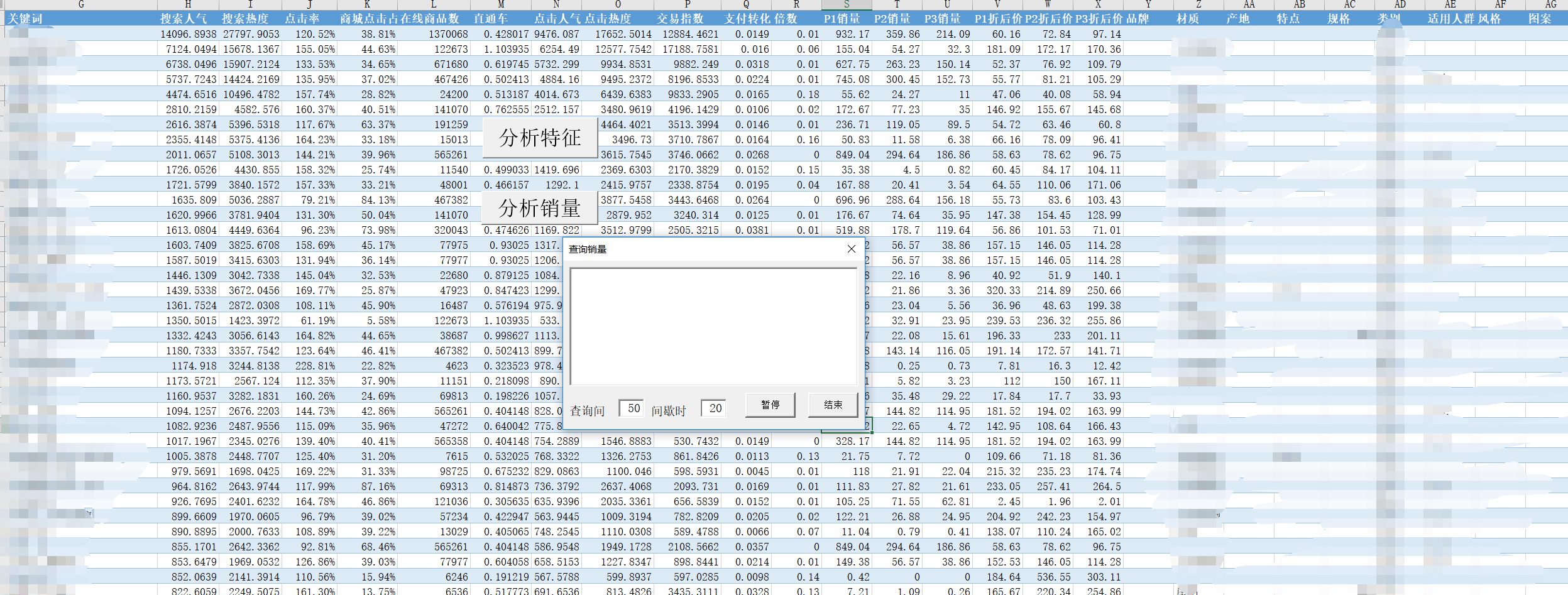
代码:HTTP请求与解析.bas
后来发现很多网站都不能直接请求数据,会限制,只能通过webkit模拟浏览器来操作了,在上一代的基础上开始用webkit来模拟操作。
这一代也很短命,同时我也学了python,发现webkit功能太局限了,很多功能都不行。
开始使用python,这效率,这效果,满意!
代码都很简单,就在下面,就是直接发起request,但是容易被限制访问。
代码:httpRequest.py
第七代2:
开始使用python配合浏览器来获取数据,并做好数据分析输出!
主要就是用了selenium操作浏览器,但是开始代码比较乱,后面借鉴了码栈的方法,开始做一些方法的优化,操作就简单多了。
当时淘宝已经开始大量限制爬虫了,整个过程都有完整的时间限制。
代码:webOper.py
就是用码栈了,码栈刚出来的时候还只是阿里内部使用,公开后一切开起来都是很美好,但是没有用多久就各种限制,负责人承诺的一些东西也兑现不了。。就咩有然后了。
普通用户其实选择码栈不错,但是想要深入就难了,很多东西都被限制了。
看着码栈被限制了,我就自己搞了一个看起来有点像的,很多朋友用了码栈就习惯了。
实际上就是在第七代python代码上加了一个GUI,浏览器相关的操作还是用selenium,基础GUI代码就是下面的这个,主要就是一个简单的数据操作窗口。
代码:GUI11.py
面临特别大的数据分析的时候,excel就不行了,开始用python做分析工具,但是不是每个电脑都用python分析环境,所以就上了私人服务器。
写好分析模型,随时可以在网页上看数据。
http://kinrt.top:8081/
pyside版本来了,自己用webkit写了浏览器,各种模仿码栈的功能都是自己写的代码,用起来顺手多了。
selenium操作浏览器用久了就发现各种兼容性问题,还有自己想要拓展的功能基本上都不行,然后就下定决心写一个自己的浏览器。
这个版本核心就是浏览器这块的操作,比如截图,拦截ajax请求,伪装浏览器,设置代理,这些都是以前实现不了的。
关于拦截ajax请求的数据,就只有pyside1可以用QNetworkAccessManager获取记录数据,pyside2就不行了。
浏览器代码就在下面,喜欢的可以看一下。
代码:browser3.py
pyside2版本来了,webkit在操作淘宝等很多后台的时候都不能加载好页面,所以就只能升级到chrome内核了,放弃了很多原有功能。
样子和上一代差不多,但是代码改了很多,这个不方便透露。
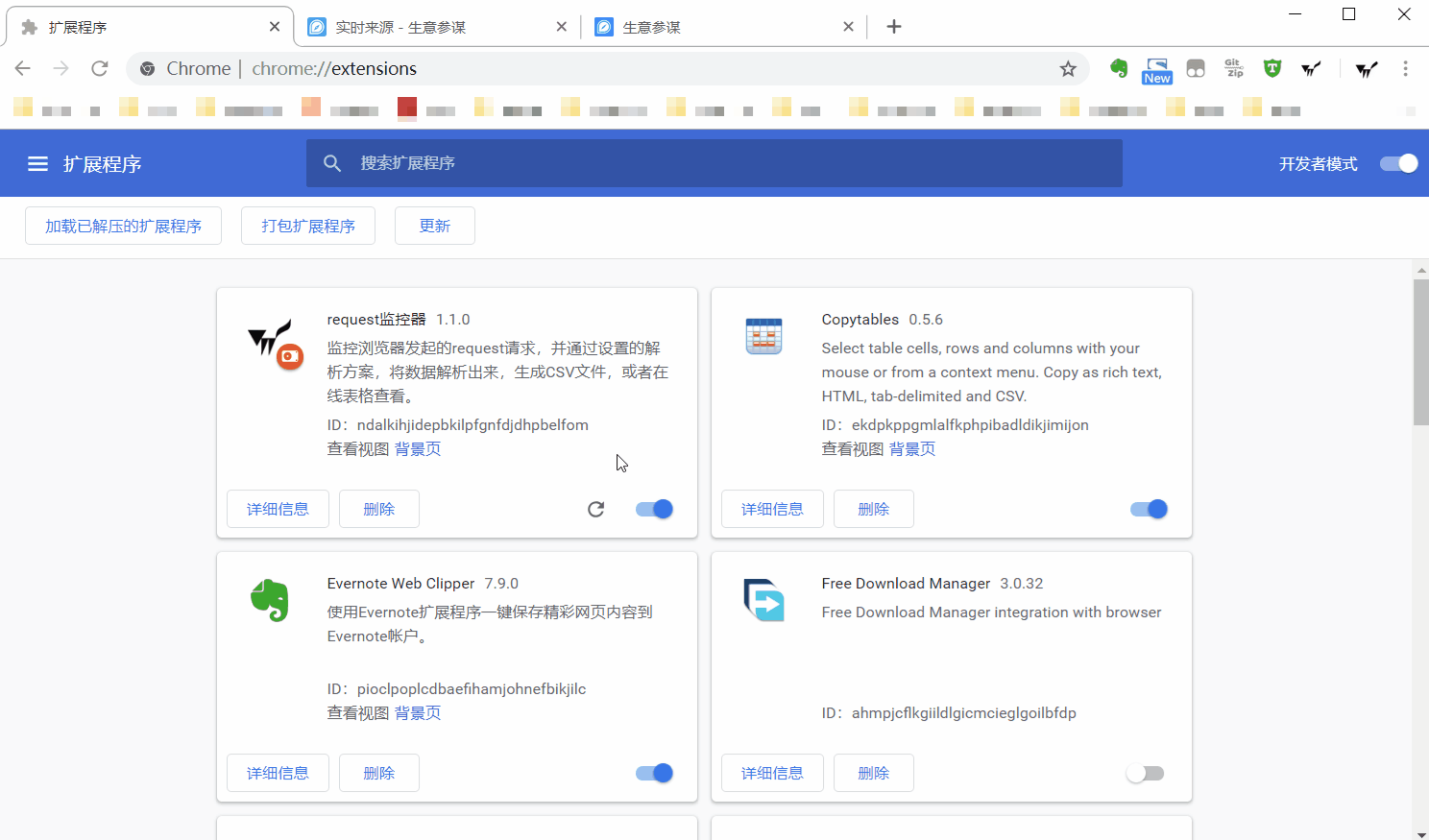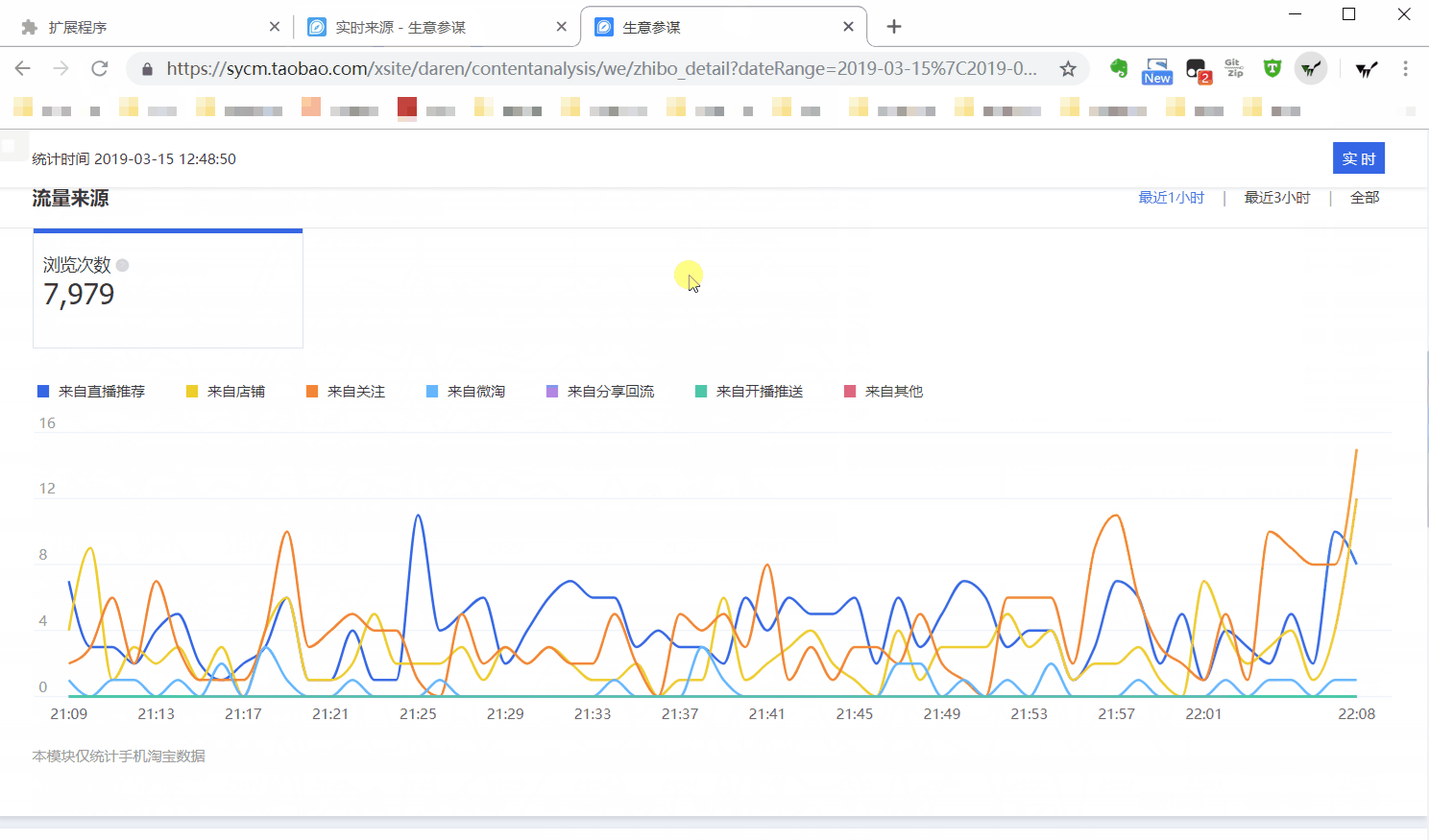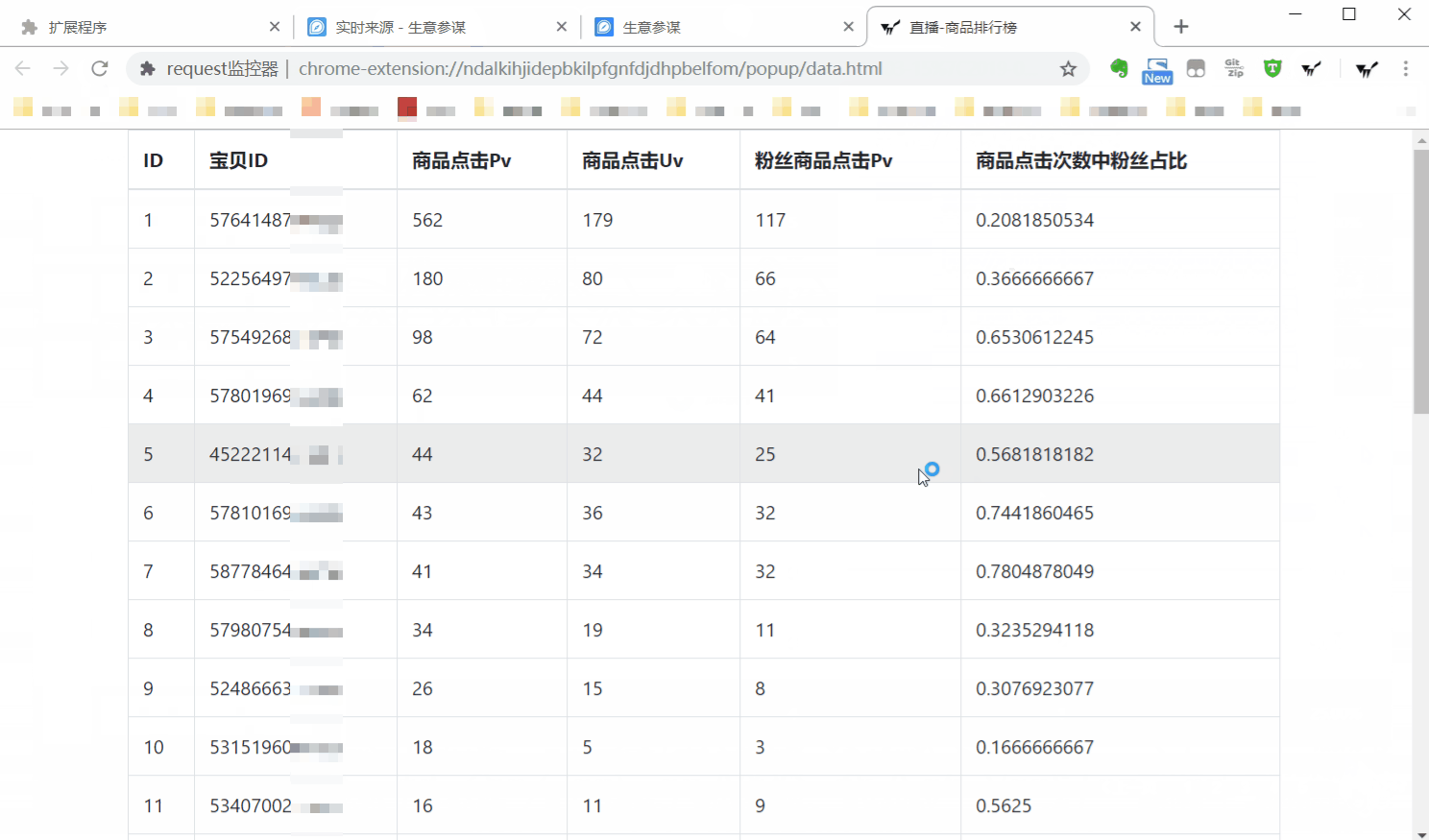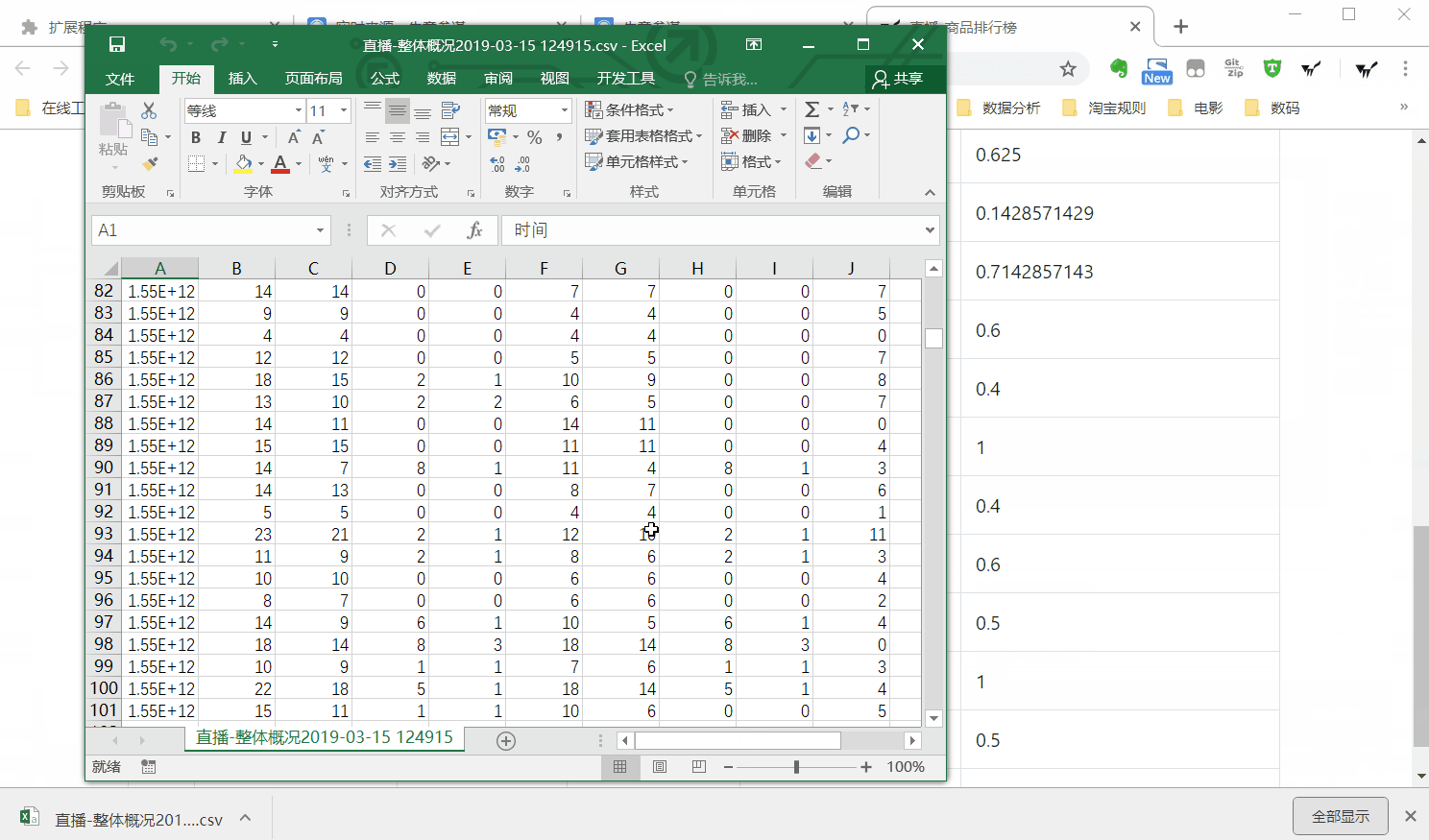
编写浏览器插件,监控自定义链接发起的网络请求,并将数据解析为表格。