电商多模态数据是什么?数据匹配方法主要有两种
小叽导读:目前学术界关于多模态的研究重点在通用领域,针对电商领域的研究相对较少。在多模态数据匹配上,使用ViLBERT 方法在通用领域的效果确实不错,但是在电商领域,由于提取的 ROI 并不理想,导致效果低于预期。本文提出了一种图文匹配模型——FashionBERT,其核心问题是如何解决电商领域图像特征的提取或者表达,分享了模型的整体结构及算法,以及在业务上的应用效果和实验数据提升。该论文已经被信息检索领域国际顶级会议 SIGIR20 Industry Track 接收。文末福利:贾扬清分享人工智能算法和系统的进化。

背景
随着 Web 技术发展,互联网上包含大量的多模态信息(包括文本,图像,语音,视频等)。从海量多模态信息搜索出重要信息一直是学术界研究重点。多模态匹配核心就是图文匹配技术 (Text and Image Matching),这也是一项基础研究,在非常多的领域有很多应用,例如图文检索 (Cross-modality IR),图像标题生成 (Image Caption),图像问答系统 (Vision Question Answering), 图像知识推理 (Visual Commonsense Reasoning)。但是目前学术界研究重点放在通用领域的多模态研究,针对电商领域的多模态研究相对较少,然而电商领域也非常需要多模态匹配模型,应用场景特别多。本文重点关注电商领域图文多模态技术研究。
多模态匹配研究简史
跨模态研究核心重点在于如何将多模态数据匹配上,即如何将多模态信息映射到统一的表征空间。早期研究主要分成两条主线:Canonical Correlation Analysis (CCA) 和Visual Semantic Embedding (VSE)。
CCA 系列方法
主要是通过分析图像和文本的 correlation,然后将图像和文本到同一空间。这一系列的问题论文完美,但是效果相对深度学习方法还是有待提高的。虽然后期也有基于深度学习的方案 (DCCA),但是对比后面的 VSE 方法还有一定差距。
VSE 系统方法
将图像和文本分别表示成 Latent Embedding,然后将多模态 Latent Embedding 拟合到同一空间。VSE 方法又延伸出来非常多的方法例如 SCAN,PFAN。这些方法在通用图文匹配上已经拿到不错效果。
随着 pre-training 和 self-supervised 技术在 CV 和 NLP领域的应用。2019 年开始,有学者开始尝试基于大规模数据,使用预训练的 BERT 模型将图文信息拟合同一空间。这些方法在通用领域取得很好的效果,这一系列的方法可以参看 VLBERT 这篇 Paper。
基于 BERT 的预训练图文模型的主要流程:
1)利用图像目标检测技术先识别图像中的 Region of Interests(RoIs)。
2)把 ROI 当做图像的 token,和文本 token 做 BERT 多模态融合,这里面有两个方案:
Single-stream:以 VLBERT 为代表,直接将图像 token 和文本 token 放入到 BERT 做多模态融合。
Cross-stream:以 ViLBERT 为代表,将图像 token 和文本 token 先做初步的交互,然后在放入到 BERT。
我们尝试了 ViLBERT 方法,发现在通用领域效果确实不错。但是在电商领域,由于提取的 ROI 并不理想,导致效果低于预期。主要原因在于:
1)电商图像 ROI 太少
电商图像产品单一,背景简单提取 ROI 很少,如图 1(c)。统计来看,通用领域 MsCoCo 数据,每张图像可以提取 19.8 个 ROI,但是电商只能提取 6.4 个 ROI。当然我们可以强制提取最小的 ROI,比如 ViLBERT 要求在 10~36 个,VLBERT 要求 100 个。但是当设定最小提取的 ROI 后,又提取了太多了重复的 ROI,可以看图 1(e)。
2)电商 ROI 不够 fine-grained
电商图像单一,提取的 RoIs 主要是 object-level 的产品 (例如,整体连衣裙,T-shirt 等) 。相对文本来说,不够细粒度 fine-grain,比如文本里面可以描述主体非常细节属性 (如,圆领,九分裤,七分裤等等)。这就导致图像 ROI 不足以和文本 token 匹配,大家可以对比一下电商领域的图 1(c) 和图 1(d)。再看下通用领域的图 1(a) 和图 1(b),你会发现通用领域简单一些,只要能将图像中的主体和文本 token alignment 到一起,基本不会太差。
3)电商图像 ROI 噪音太大
如图 1(f) 中提取的模特头,头发,手指,对于商品匹配来说用处不大。
这也就解释了,电商领域也采用现有的 ROI 方式,并不能得到非常理想的结果。如果说,针对电商领域重新训练一个电商领域的 ROI 提取模型,需要大量的数据标注工作。那么有没有简单易行的方法做图文匹配拟合。



图1: 电商领域 ROI 问题
FashionBERT 图文匹配模型
本文我们提出了 FashionBERT 图文匹配模型,核心问题是如何解决电商领域图像特征的提取或者表达。Google 在 2019 年年中发表了一篇文章图像自监督学习模型 selfie,主要思路是将图像分割成子图,然后预测子图位置信息。从而使模型达到理解图像特征的目的,这个工作对我们启发很大。我们直接将图像 split 相同大小的 Patch,然后将 Patch 作为图像的 token,和文本进行拟合,如图二所示。使用 Patch 的好处:
图像 Patch 包含了所有图像的细节信息。
图像 Patch 不会出现重复的 ROI 或者太多无用的 ROI。
图像 Patch 是天然包含顺序的,所以解决 BERT 的 sequence 问题。
FashionBERT 整体结构如图 2,主要包括 Text Embedding, Patch Embedding, Cross-modality FashionBERT,以及 Pretrain Tasks。
Text Embedding
和原始 BERT 一样,先将句子分成 Token,然后我们采用 Whole Word Masking 技术将整个 Token 进行 masking。Masking 的策略和原始的 BERT 保持一致。
Patch Embedding
和 Text Embedding 类似,这里我们将图片平均分成 8*8 个 patch。每个 Patch 经过 ResNet 提取 patch 的图像特征,我们提取 2048 维图像特征。Patch mask 策略,我们随机 masked 10% 的 patch,masked 的 patch 用 0 代替。同时在 Segment 字段我们分别用 "T" 和 "I" 区分文 本token 输入和图像 patch 输入。
Cross-modality FashionBERT
采用预训练的 BERT 为网络,这样语言模型天然包含在 FashionBERT 中。模型可以更加关注图文匹配融合。
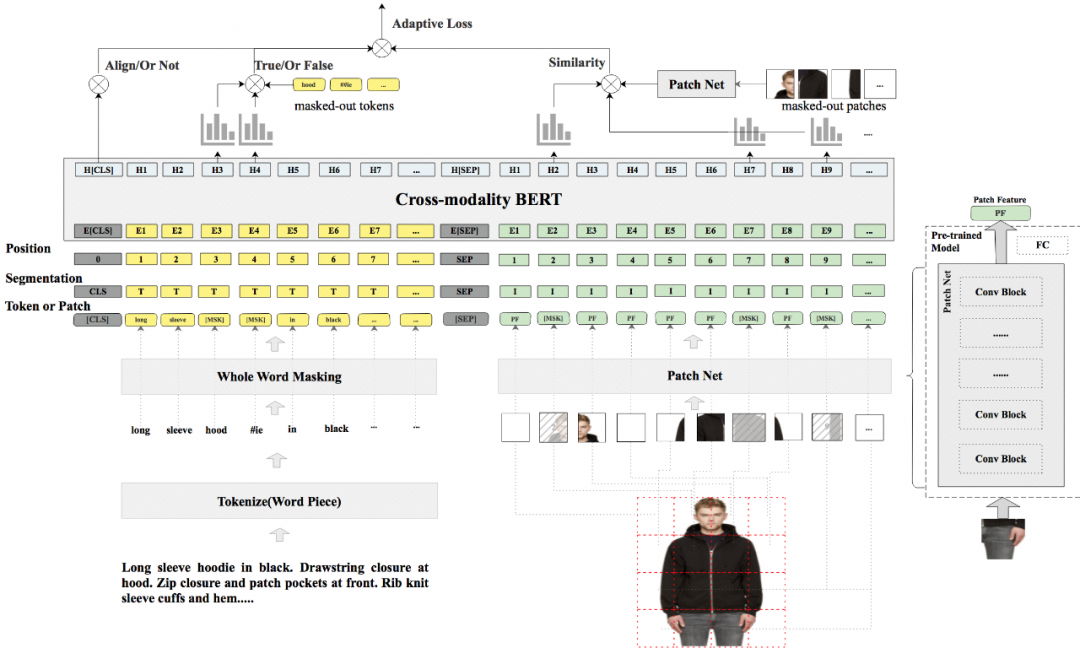
图2: FashionBERT 主要框架
FashionBERT 模型在 pretrain 阶段,总共包含了三个任务:
1 Masked Language Modeling (MLM)
预测 Masked Text Token,这个任务训练和参数我们保持和原始的 BERT 一致。
2 Masked Patch Modeling (MPM)
预测 Masked Patch,这个任务和 MLM 类似。但是由于图像中没有 id 化的 token。这里我们用 patch 作为目标,希望 BERT 可以重构 patch 信息,这里我们选用了 KLD 作为 loss 函数。
3 Text and Image Alignment
和 Next Sentence Prediction 任务类似,预测图文是否匹配。正样本是产品标题和图片,负样本我们随机采样同类目下其他产品的图片作为负样本。
这是一个多任务学习问题,如何平衡这些任务的学习权重呢?另外,还有一个问题,目前很多实验指出 BERT 中 NSP 的效果并不一定非常有效,对最终的结果的影响不是特别明朗。但是对于图文匹配来说,Text and Image Alignment 这个 loss 是至关重要的。那么如何平衡这几个任务的学习呢?这里我们提出 adaptive loss 算法,我们将学习任务的权重看做是一个新的优化问题,如图 3 所示。FashionBERT 的 loss 是整体 loss 的加和,由于只有三个任务,其实我们可以直接得到任务权重 W 的解析解(具体的求解过程可以参考我们论文,这里不再赘述)。
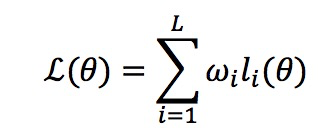
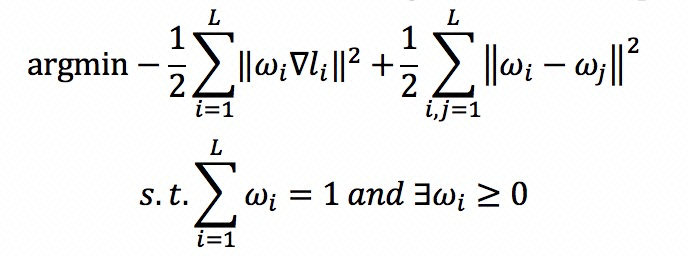
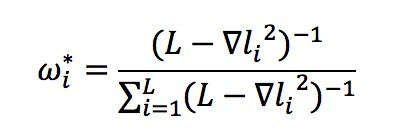
图3: Adaptive Loss
整个 w 的学习过程可以看做是一个学生想学习三门功课,w 的作用是控制学习的关注度,一方面控制别偏科,一方面总成绩要达到最高。具体 adaptive loss 算法,可以参看论文。从实际的效果来看 w,随着训练的迭代关注不同的任务,达到对任务做平衡的目的。
业务应用
目前 FashionBERT 已经开始在 Alibaba 搜索多模态向量检索上应用,对于搜索多模态向量检索来说,匹配任务可以看成是一个文文图匹配任务,即 User Query (Text)-Product Title (Text) - Product Image (Image) 三元匹配关系。FashionBERT 从上面的模型可以看到是一个基础的图文匹配模型,因此我们做了 Continue Pretrain 工作,同时加入 Query,Title,Image Segment 区分,如图四所示。和 FashionBERT 最大的区别在于我们引入三个 segment 类型,“Q”,“T”,“I” 分别代表 Query,Title,Image。
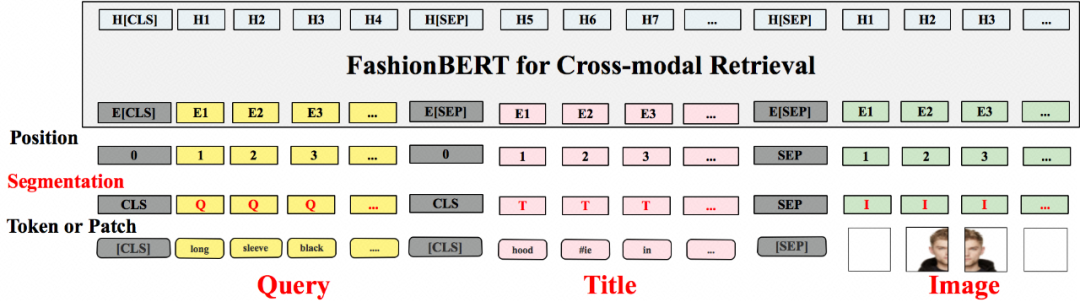
图4: FashionBERT Continue Pretrain
Continue Pretrain 之后的模型可以在非常小的 finetune 数据上就快速拿到非常不错的效果。目前我们向量检索模型如下图 5:
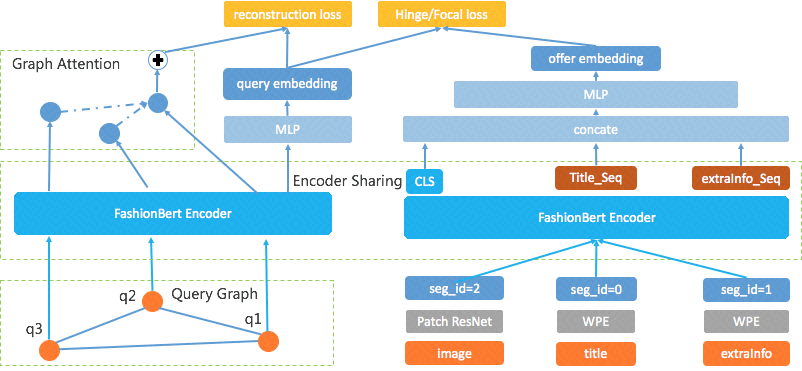
图5: 向量检索 3.0 多模态强交互匹配模型
上图中我们采用双塔模型 (塔之间参数共享),这样可以方便在线 Query 向量生成和离线的产品向量生成。另外在 Query 侧,我们用共现的 Query 辅助 Query 的特征表达,在产品侧,我们用扩展信息扩大产品语义表达。
实验效果
公开数据集
我们采用 FashionGen 数据集,对比了主流图文匹配技术,以及最新的 ViLBERT 和 VLBERT,在图文匹配和 Cross-modality Retrieval 效果如下,FashionBERT 取得非常明显的提升。
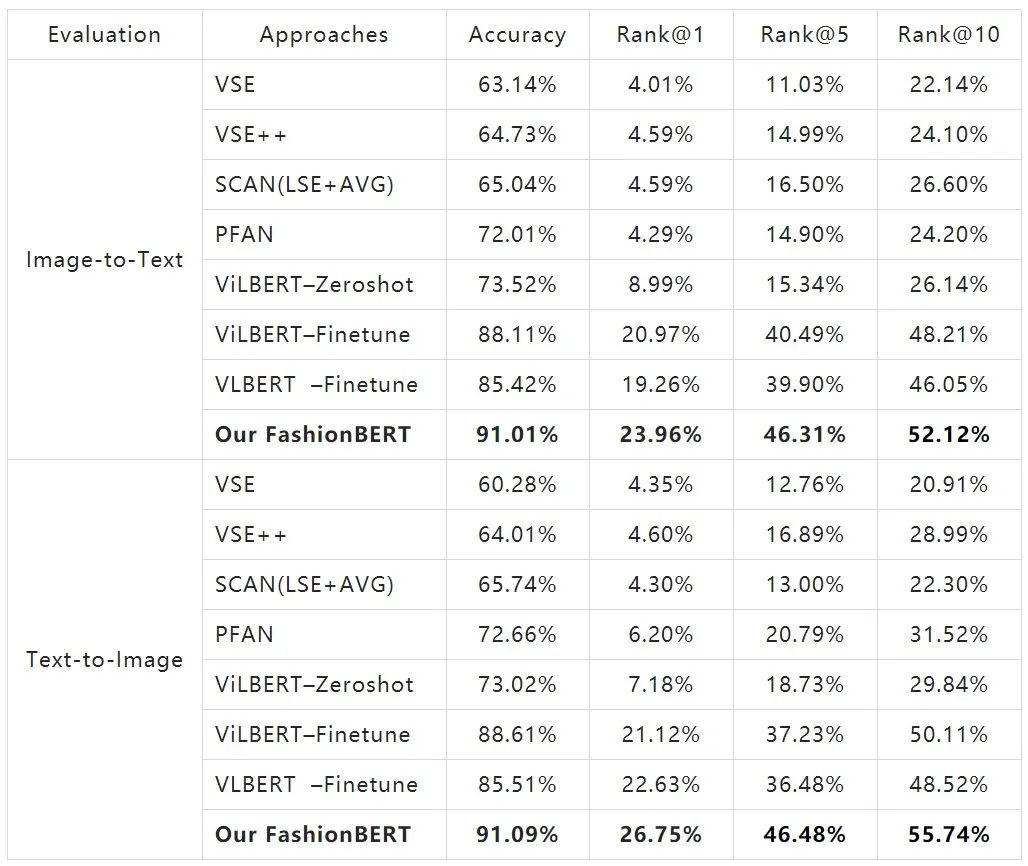
ICBU 数据上
对比 BERT 模型,效果提升也非常明显。同时由于线上预测性能问题,finetune 模型做了模型约减,我们只用了 FashionBERT 前两层,同时引入缓存,动态可变长度 Variable Sequence Length (VSL) 策略,这样大大提升了 FashionBERT 线上服务性能。如下表所示。
目前论文已经被信息检索领域国际顶级会议 SIGIR20 Industry Track 中接收。预印版本见这里:https://arxiv.org/abs/2005.09801。感兴趣的同学后续可以看我们的论文,有更加详细的对比。
后续规划
图文匹配方向虽然已经有很长的研究历史了,但是基于 pretrain BERT 的方式还方兴未艾。后续我们计划在四个方面进行进一步优化:
图像多尺度变化:多图像做多尺度变化,获取不同尺度下图像细粒度特征。
文本 & 图像对齐:引入其他信息或者其他方式,在预训练过程中对文本 token 和图像区域做一定的对齐。
行业知识引入:引入行业知识,学习不同行业下图文匹配模型。
视频理解:做文本,图像,视频多模态理解。
相信基于 BERT 的强大拟合能力,多模态信息的匹配融合会越来越智能。
最后想说的是,我们招人!我所在的部门是新零售技术事业群,主要负责 alibaba.com 网站和 APP 的搜索、推荐、商品等领域相关的算法工作。非常期待具备机器学习 / 自然语言处理 / 图像处理 / 数据挖掘背景的同学加入。有意向的同学可以把简历发到我的邮箱中 dehong.gdh@alibaba-inc.com。
贾扬清直播分享
人工智能算法和系统的进化
贾扬清,曾任 Facebook AI 架构部门总监、Google Brain 研究科学家,Caffe 之父,TensorFlow 的作者之一,加州大学伯克利分校计算机科学博士学位,通过本次分享,介绍人工智能在近几年当中的算法和相应系统的进化过程,同时从技术角度阐述产品形态和用户场景。

