MySQL索引以及查询优化的详细介绍
本篇文章给大家带来的内容是关于MySQL索引以及查询优化的详细介绍,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
文章《MySQL查询分析》讲述了使用MySQL慢查询和explain命令来定位mysql性能瓶颈的方法,定位出性能瓶颈的sql语句后,则需要对低效的sql语句进行优化。本文主要讨论MySQL索引原理及常用的sql查询优化。
一个简单的对比测试
前面的案例中,c2c_zwdb.t_file_count表只有一个自增id,FFileName字段未加索引的sql执行情况如下:

在上图中,type=all,key=null,rows=33777。该sql未使用索引,是一个效率非常低的全表扫描。如果加上联合查询和其他一些约束条件,数据库会疯狂的消耗内存,并且会影响前端程序的执行。
这时给FFileName字段添加一个索引:
alter table c2c_zwdb.t_file_count add index index_title(FFileName);
再次执行上述查询语句,其对比很明显:

在该图中,type=ref,key=索引名(index_title),rows=1。该sql使用了索引index_title,且是一个常数扫描,根据索引只扫描了一行。
比起未加索引的情况,加了索引后,查询效率对比非常明显。MySQL索引通过上面的对比测试可以看出,索引是快速搜索的关键。MySQL索引的建立对于MySQL的高效运行是很重要的。对于少量的数据,没有合适的索引影响不是很大,但是,当随着数据量的增加,性能会急剧下降。如果对多列进行索引(组合索引),列的顺序非常重要,MySQL仅能对索引最左边的前缀进行有效的查找。
下面介绍几种常见的MySQL索引类型。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。1、MySQL索引类型(1) 主键索引 PRIMARY KEY
它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引。
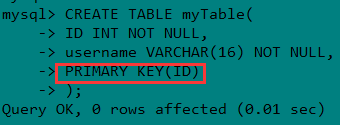
当然也可以用 ALTER 命令。记住:一个表只能有一个主键。
(2) 唯一索引 UNIQUE
唯一索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD UNIQUE (column)
(3) 普通索引 INDEX
这是最基本的索引,它没有任何限制。可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD INDEX index_name (column)
(4) 组合索引 INDEX
组合索引,即一个索引包含多个列。可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3)
(5) 全文索引 FULLTEXT
全文索引(也称全文检索)是目前搜索引擎使用的一种关键技术。它能够利用分词技术等多种算法智能分析出文本文字中关键字词的频率及重要性,然后按照一定的算法规则智能地筛选出我们想要的搜索结果。
可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD FULLTEXT (column)2、索引结构及原理mysql中普遍使用B+Tree做索引,但在实现上又根据聚簇索引和非聚簇索引而不同,本文暂不讨论这点。
b+树介绍
下面这张b+树的图片在很多地方可以看到,之所以在这里也选取这张,是因为觉得这张图片可以很好的诠释索引的查找过程。
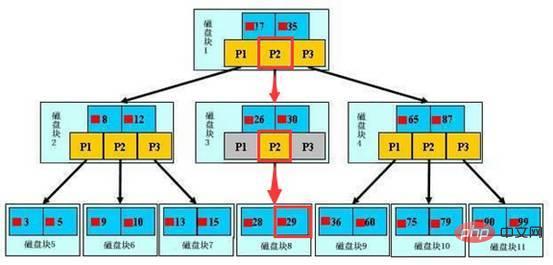
如上图,是一颗b+树。浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。
真实的数据存在于叶子节点,即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
查找过程
在上图中,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
性质
(1) 索引字段要尽量的小。
通过上面b+树的查找过程,或者通过真实的数据存在于叶子节点这个事实可知,IO次数取决于b+数的高度h。
假设当前数据表的数据量为N,每个磁盘块的数据项的数量是m,则树高h=3

