redis单线程为什么执行速度这么快

Redis之所以执行速度很快,主要依赖于以下几个原因:
(一)纯内存操作,避免大量访问数据库,减少直接读取磁盘数据,redis将数据储存在内存里面,读写数据的时候都不会受到硬盘 I/O 速度的限制,所以速度快;
(二)单线程操作,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
(三)采用了非阻塞I/O多路复用机制
多路复用原理:
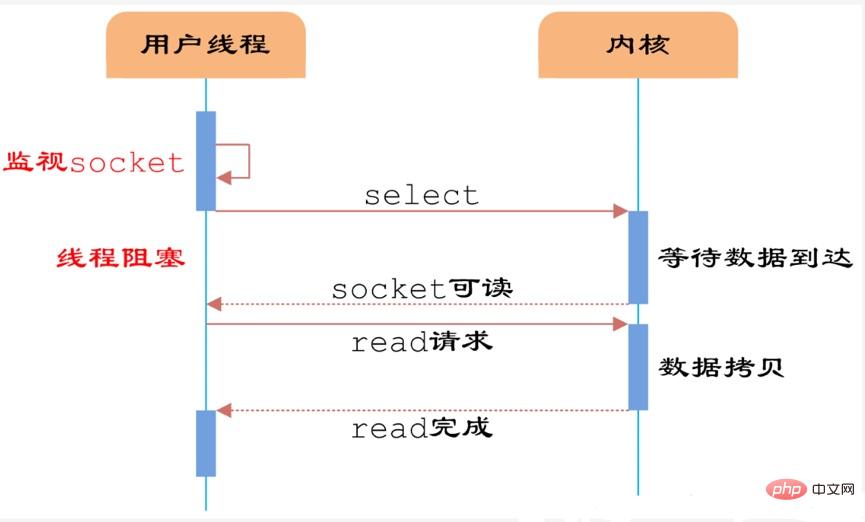
用户首先将需要进行IO操作的socket添加到select中,然后阻塞等待select系统调用返回。当数据到达时,socket被激活,select函数返回。用户线程正式发起read请求,读取数据并继续执行。这样用户可以注册多个socket,然后不断地调用select读取被激活的socket,redis服务端将这些socke置于队列中,然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中,提高读取效率。
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作,从而提高效率。
(四)灵活多样的数据结构。
redis内部使用一个redisObject对象来表示所有的key和value。redisObject主要的信息包括数据类型、编码方式、数据指针、虚拟内存等。它包含String,Hash,List,Set,Sorted Set五种数据类型,针对不同的场景使用对应的数据类型,减少内存使用的同时,节省网络流量传输。
(五)持久化
由于redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据。redis提供两种方式进行持久化,一种是RDB持久化(原理是将redis在内存中的数据库记录定时 dump到磁盘上的RDB持久化),另外一种是AOF(append only file)持久化(原理是将redis的操作日志以追加的方式写入文件)。持久化似乎和redis的速度快并没有直接关系,但是这保证的redis数据的安全性和可靠性,也起到数据备份的作用。
(六)总结
试想单线程是否就无法发挥多核CPU 性能,其实不然,我们可以通过在单机开多个redis实例来完善。单一线程只能用到一个CPU核心,所以可以在同一个多核的服务器中,启动多个实例,组成master-master或者master-slave的形式,耗时的读命令可以完全在slave进行,充分发挥redis的作用。
单线程指的是网络请求模块使用了一个线程(所以不需考虑并发安全性),其他模块也会用到多个线程,使用redis的过程中充分发挥其优势,避免一些不当操作,导致性能下降。
更多Redis相关知识,请访问Redis使用教程栏目!以上就是redis单线程为什么执行速度这么快的详细内容,更多请关注小潘博客其它相关文章!

