详解Redis的LRU算法
下面由Redis教程栏目给大家详解Redis的LRU算法,希望对需要的朋友有所帮助!
 Redis的LRU算法LRU算法背后的的思想在计算机科学中无处不在,它与程序的"局部性原理"很相似。在生产环境中,虽然有Redis内存使用告警,但是了解一下Redis的缓存使用策略还是很有好处的。下面是生产环境下Redis使用策略:最大可用内存限制为4GB,采用 allkeys-lru 删除策略。所谓删除策略:当redis使用已经达到了最大内存,比如4GB时,如果这时候再往redis里面添加新的Key,那么Redis将选择一个Key删除。那如何选择合适的Key删除呢?
Redis的LRU算法LRU算法背后的的思想在计算机科学中无处不在,它与程序的"局部性原理"很相似。在生产环境中,虽然有Redis内存使用告警,但是了解一下Redis的缓存使用策略还是很有好处的。下面是生产环境下Redis使用策略:最大可用内存限制为4GB,采用 allkeys-lru 删除策略。所谓删除策略:当redis使用已经达到了最大内存,比如4GB时,如果这时候再往redis里面添加新的Key,那么Redis将选择一个Key删除。那如何选择合适的Key删除呢?
在官方文档Using Redis as an LRU cache描述中,提供了好几种删除策略,比如 allkeys-lru、volatile-lru等。在我看来按选择时考虑三个因素:随机、Key最近被访问的时间 、Key的过期时间(TTL)
比如:allkeys-lru,"统计一下所有的"Key历史访问的时间,把"最老"的那个Key移除。注意:我这里加了引号,其实在redis的具体实现中,要统计所有的Key的最近访问时间代价是很大的。想想,如何做到呢?
再比如:allkeys-random,就是随机选择一个Key,将之移除。
再比如:volatile-lru,它只移除那些使用 expire 命令设置了过期时间的Key,根据LRU算法来移除。
再比如:volatile-ttl,它只移除那些使用 expire 命令设置了过期时间的Key,哪个Key的 存活时间(TTL KEY 越小)越短,就优先移除。
volatile 策略(eviction methods) 作用的Key 是那些设置了过期时间的Key。在redisDb结构体中,定义了一个名为 expires 字典(dict)保存所有的那些用expire命令设置了过期时间的key,其中expires字典的键指向redis 数据库键空间(redisServer--->redisDb--->redisObject)中的某个键,而expires字典的值则是这个键的过期时间(long类型整数)。额外提一下:redis 数据库键空间是指:在结构体redisDb中定义的一个名为"dict",类型为hash字典的一个指针,它用来保存该redis DB中的每一个键对象、以及相应的值对象。
既然有这么多策略,那我用哪个好呢?这就涉及到Redis中的Key的访问模式了(access-pattern),access-pattern与代码业务逻辑相关,比如说符合某种特征的Key经常被访问,而另一些Key却不怎么用到。如果所有的Key都可能机会均等地被我们的应用程序访问,那它的访问模式服从均匀分布;而大部分情况下,访问模式服从幂指分布(power-law distribution),另外Key的访问模式也有可能是随着时间变化的,因此需要一种合适的删除策略能够catch 住 (捕获住)各种情形。而在幂指分布下,LRU是一种很好的策略:Redis中LRU策略的实现最直观的想法:LRU啊,记录下每个key 最近一次的访问时间(比如unix timestamp),unix timestamp最小的Key,就是最近未使用的,把这个Key移除。看下来一个HashMap就能搞定啊。是的,但是首先需要存储每个Key和它的timestamp。其次,还要比较timestamp得出最小值。代价很大,不现实啊。
第二种方法:换个角度,不记录具体的访问时间点(unix timestamp),而是记录idle time:idle time越小,意味着是最近被访问的。
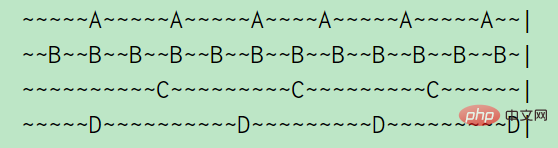
比如A、B、C、D四个Key,A每5s访问一次,B每2s访问一次,C和D每10s访问一次。(一个波浪号代表1s),从上图中可看出:A的空闲时间是2s,B的idle time是1s,C的idle time是5s,D刚刚访问了所以idle time是0s
这里,用一个双向链表(linkedlist)把所有的Key链表起来,如果一个Key被访问了,将就这个Key移到链表的表头,而要移除Key时,直接从表尾移除。
但是在redis中,并没有采用这种方式实现,它嫌LinkedList占用的空间太大了。Redis并不是直接基于字符串、链表、字典等数据结构来实现KV数据库,而是在这些数据结构上创建了一个对象系统Redis Object。在redisObject结构体中定义了一个长度24bit的unsigned类型的字段,用来存储对象最后一次被命令程序访问的时间:
毕竟,并不需要一个完全准确的LRU算法,就算移除了一个最近访问过的Key,影响也不太。
最初Redis是这样实现的:
随机选三个Key,把idle time最大的那个Key移除。后来,把3改成可配置的一个参数,默认为N=5:maxmemory-samples 5
就是这么简单,简单得让人不敢相信了,而且十分有效。但它还是有缺点的:每次随机选择的时候,并没有利用历史信息。在每一轮移除(evict)一个Key时,随机从N个里面选一个Key,移除idle time最大的那个Key;下一轮又是随机从N个里面选一个Key...有没有想过:在上一轮移除Key的过程中,其实是知道了N个Key的idle time的情况的,那我能不能在下一轮移除Key时,利用好上一轮知晓的一些信息?
start from scratch太傻了。于是Redis又做出了改进:采用缓冲池(pooling)
当每一轮移除Key时,拿到了这个N个Key的idle time,如果它的idle time比 pool 里面的 Key的idle time还要大,就把它添加到pool里面去。这样一来,每次移除的Key并不仅仅是随机选择的N个Key里面最大的,而且还是pool里面idle time最大的,并且:pool 里面的Key是经过多轮比较筛选的,它的idle time 在概率上比随机获取的Key的idle time要大,可以这么理解:pool 里面的Key 保留了"历史经验信息"。
采用"pool",把一个全局排序问题 转化成为了 局部的比较问题。(尽管排序本质上也是比较,V

